数据容器(一) Pandas库备忘
本文最后更新于:2023年4月10日 上午
1. 数据读写
数据读入
1 | |
数据写入
1 | |
2. 数据结构
-
Series,一维数组,pandas.Series( data, index, dtype, name, copy) -
DataFrame,二维数组,pandas.DataFrame( data, index, columns, dtype, copy)<index>:行标签<columns>:列标签
df.values可将DataFrame转为ndarry返回
索引切片
设置索引
1 | |
1 | |
查询数组行/列标签情况
1 | |
按行索引/切片
-
索引
df.iloc1
2df.iloc[0] # series
df.iloc[[0]] # dataframe -
切片
df[] / df.iloc1
2
3
4
5# 连续多行,前开后闭
df[2:3] # data frame
df.iloc[2:3] # data frame
# 不连续多行
df.iloc[[1,3]] # data frame
按列索引/切片
-
df[] / df.loc[] / df.iloc[]1
2
3
4
5
6
7
8
9# series
testdf3['A'] # 按列名索引得到单列
testdf3.loc[:,'A'] # 按列名索引得到单列
testdf3.iloc[:,0] # 按列index索引得到单列
# data frame
testdf3[['A','B']] # 按列名索引得到单/多列
testdf3.loc[:,['A','B']] # 按列名索引得到单/多列
testdf3.iloc[:,[0, 1]] # 按列index索引得到单/多列
行列同时索引/切片
-
df.loc[] / df.iloc[]1
2
3
4
5
6
7
8
9
10df.iloc[<行>,<列>]
df.iloc[[1,3],0] # 1. series
df.iloc[[1,3],[0]] # 2. dataframe
df.iloc[[1,3],[1,3]] # 2. dataframe
df.iloc[[1,3],1:3] # 3. dataframe
df.loc[1,["A","D"]] # series 对应上述1
df.loc[[1],["A","D"]] # df 对应上述2
df.loc[[1,3],["A","D"]] # df 对应上述2
df.loc[[1,3],"A":"D"] # df 对应上述3df.loc按名称,df.iloc按index。
基本信息
查询数据的基本信息
-
查询数据前/后片段
1
2df.head(n) # 前n行
df.tail(n) # 尾n行 -
查询数据维度 (行/列总数)
1
df.shape # (3453, 27) -
查询数据类型 / 索引
1
df.dtypes # 各列数据类型 -
查询行/列信息
1
2df.index
df.columns -
查询数据总体情况
1
2
3
4
5# 非零值、数据类型
df.info()
# 统计值
df.describe()
3. 数据类型
时间类型
Timestamp时间戳
1 | |
Period时间段
4. 数据操作
删除、修改、合并
1 | |
计数、排序、唯一
1 | |
运算
1 | |
按条件选取
1 | |
划分求值
类似于数据库的GROUPBY,得到一个DataFrameGroupBy对象,可以对此对象进行后续操作,如:数据库里的聚合函数
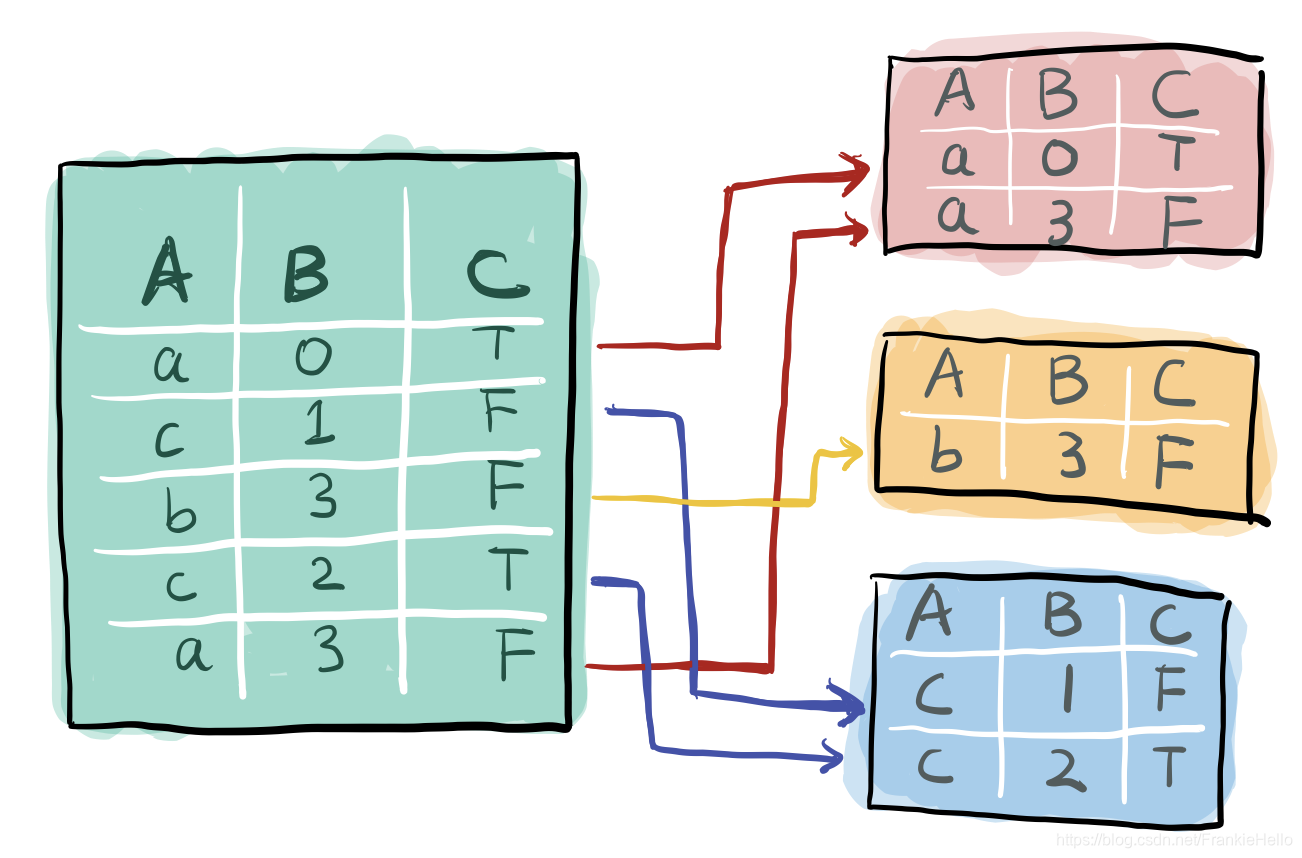
1 | |
转换
ndarray
1 | |
4. 数据清洗
缺失值
线下csv文件,空格在DataFrame里边也是用的“NaN”表示。
1 | |
缺失值填补
1 | |
重复值
1 | |
独热编码
1 | |
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!