数据库(三) 数据库设计规范
本文最后更新于:2023年2月28日 下午
设计中的问题
- 插入异常 (insert abnormity)
- 删除异常 (delete abnormity)
- 更新异常 (hard to update)
- 数据冗余 (redundant data)
关系型数据库的设计就是根据函数依赖和多值依赖把关系模式拆解成符合数据库设计范式的关系模式。
关系模式
Student<U,F>属性组
U={字段1,字段2,...}函数依赖组
F={函数依赖1,函数依赖2,...}
函数依赖
函数依赖 (Functional Dependencies)
函数依赖为
X->Y时,X: Determinant/Y: Dependent。for same X , value of Y should be same. for different X, value of Y could be same or different. (Y唯一决定于X)
平凡函数依赖 (Trivial functional dependency)
当函数依赖
X->Y中,Y是X的子集。
非平凡函数依赖 (Non-trivial functional dependency)
当函数依赖
X->Y中,Y不是X的子集。
完全函数依赖 (Full functional Dependency)
当函数依赖
X->Y中,Y不可以函数依赖于X的某一真子集。
部分函数依赖 (Partial functional Dependency)
当函数依赖
X->Y中,Y可以函数依赖于X的某一真子集。如
(Sno,Cno)→Sdept中存在Sno →Sdept,则其为部分函数依赖。
传递函数依赖 (Transitive functional Dependency)
- 当
X->Y,且Y !->X时,若有Y->Z,则存在传递函数依赖X->Z- 当
X->Y,且Y ->X时,若有Y->Z,则X->Z为直接函数依赖
多值依赖
多值依赖 (Multivalued Dependencies)
关系型数据库设计范式
Normalization theory is the theoretical basis for logical design of relational database.
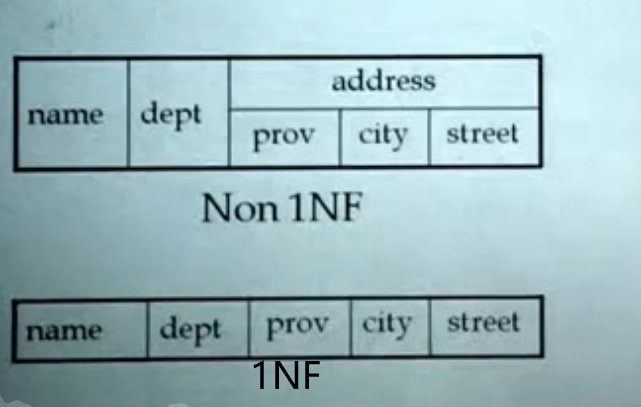
1NF
第一范式:数据库表中的所有字段值都是不可分解的原子值。
1NF (First Normal Form): every attribute of a relation must be atomic.
即不得存在字段的嵌套关系:
2NF
第二范式:建立在第一范式的基础之上,确保数据库表中的每一列都和主键相关(无部分函数依赖关系)。
1 | |
如该表中 ①S# -> SNAME, AGE, ADDR ; ②(S#, C#) -> GRADE 存在部分函数依赖关系(①):
以该表为例出现问题:
-
Insert abnormity
- 上例中,不能插入一个还未选课的学生的信息
-
Delete abnormity
- 上例中,如果一个学生把选过的课都退了,那么他的信息也会被删除
-
Hard to update
- because of redundancy, it is hard to keep consistency when update.
3NF
第三范式:建立在第二范式的基础之上,确保数据库表中的每一列都和主键直接相关(不存在属性间传递依赖)。
1 | |
如该表中 ①EMP# -> SAL_LEVEL ; ②SAL_LEVEL -> SALARY 雇员编号和薪水间存在传递依赖的关系:

以该表为例出现的问题:
-
Insert abnormity
- 无员工信息时也没有薪水级别与薪水的对应信息
-
Delete abnormity
- 若某薪水级别只有一个员工,删除该员工信息,对应的薪水级别信息也被删除
-
Hard to update
- because of redundancy, it is hard to keep consistency when update.
BCNF
ER图
ER图(entity-relation graph)

设计流程
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!