ML工具(一) sklearn库备忘
本文最后更新于:2023年3月1日 上午
sklearn 全称 scikit-learn,是简单易行的机器学习工具。可处理以下任务板块:

1. 数据集
内置数据集
sklearn.datasets 内置部分数据集
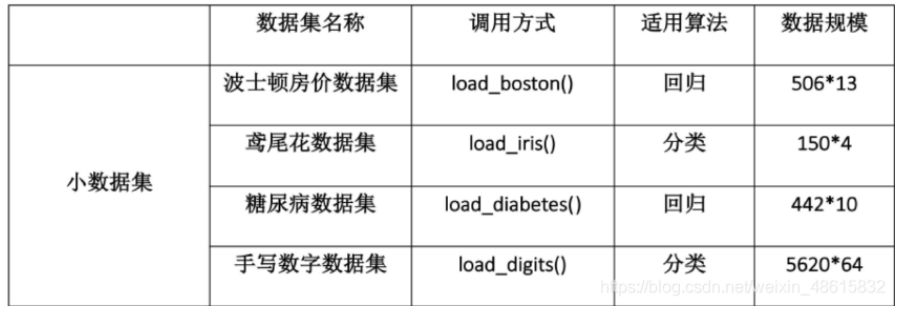
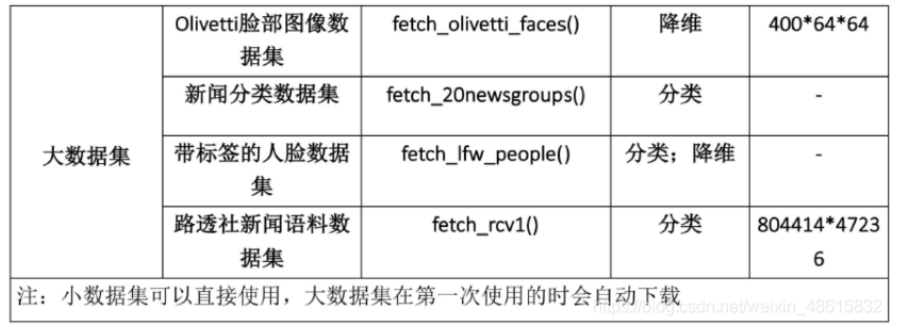
拿取数据集合
1 | |
2. 机器学习模型
基本概念
在sklearn中用来训练数据的机器学习模型,是估计器 (estimator)
-
创建模型
1
2from sklearn.linear_model import LinearRegression
model = LinearRegression(normalize=True) -
调节超参数
1
2
3
4
5
6# 设置一组超参数
normalize=True
n_clusters=3
# 访问超参数
model.normalize
model.n_clusters -
训练集拟合
1
2
3
4
5
6
7# 有监督学习
model.fit(X_train, y_train )
# 无监督学习
model.fit(X_train)
# 访问 model 里学到的参数,比如线性回归里的特征前的系数 coef_,或 K 均值里聚类标签 labels_。
model.coef_
model.labels_
在估计器上延展出预测的功能,是预测器 (predictor)
1 | |
在sklearn中用来数据预处理的机器学习模型,是转换器 (transfor)
学习模型
回归
分类
预处理模型
数据变换
归一化
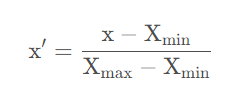
1 | |
标准化
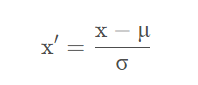
1 | |
特征组合
sklearn.preprocessing.PolynomialFeatures用来生成多项式特征,
1 | |
3. 模型验证
交叉验证是在机器学习建立模型和验证模型参数时常用的办法。交叉验证重复地使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
- 如果数据样本量小于一万条,我们采用交叉验证来训练优化选择模型
- 如果样本大于一万条的话,我们一般随机的把数据分成三份,一份为训练集(Training Set),一份为验证集(Validation Set),最后一份为测试集(Test Set)。用训练集来训练模型,用验证集来评估模型预测的好坏和选择模型及其对应的参数。把最终得到的模型再用于测试集,最终决定使用哪个模型以及对应参数。
简单交叉验证
随机的将样本数据分为训练集、测试集两部分 (train_test_split) ,训练集来训练模型,在测试集上验证模型及参数。
1 | |
K折交叉验证
K折交叉验证 (K-Folder Cross Validation) 会把样本数据随机的分成K份,每次随机的选择K-1份作为训练集,剩下的1份做测试集,重复K次。
1 | |
4. 评价指标
<estimator>的score方法:<estimator>.score()scoring参数:使用cross-validation的进行模型验证时,其函数内置scoring参数,见第一列Metric函数:调用metrics模块函数,见第二列
| scoring para | meaning | function |
|---|---|---|
'accuracy' |
分类,准确率 | from sklearn.metrics import accuracy_scoreaccuracy_score(y_true, y_pred) |
'neg_mean_squared_error' |
回归,的负值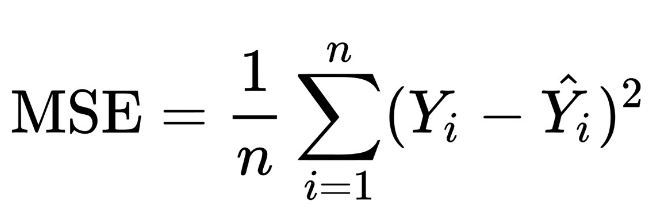 |
from sklearn.metrics import mean_squared_errormean_squared_error(y_true, y_pred) |
‘r2’ |
回归,方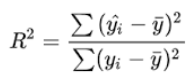 |
from sklearn.metrics import r2_scorer2_score(y_true, y_pred) |
5. 工作流
按顺序组合估计器 (estimator) / 预测器 (predictor) / 转换器 (transfor) 形成流水线,用以处理重复工作
1 | |
网格搜索
自动调参的工具,常结合pipeline使用
1 | |
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!